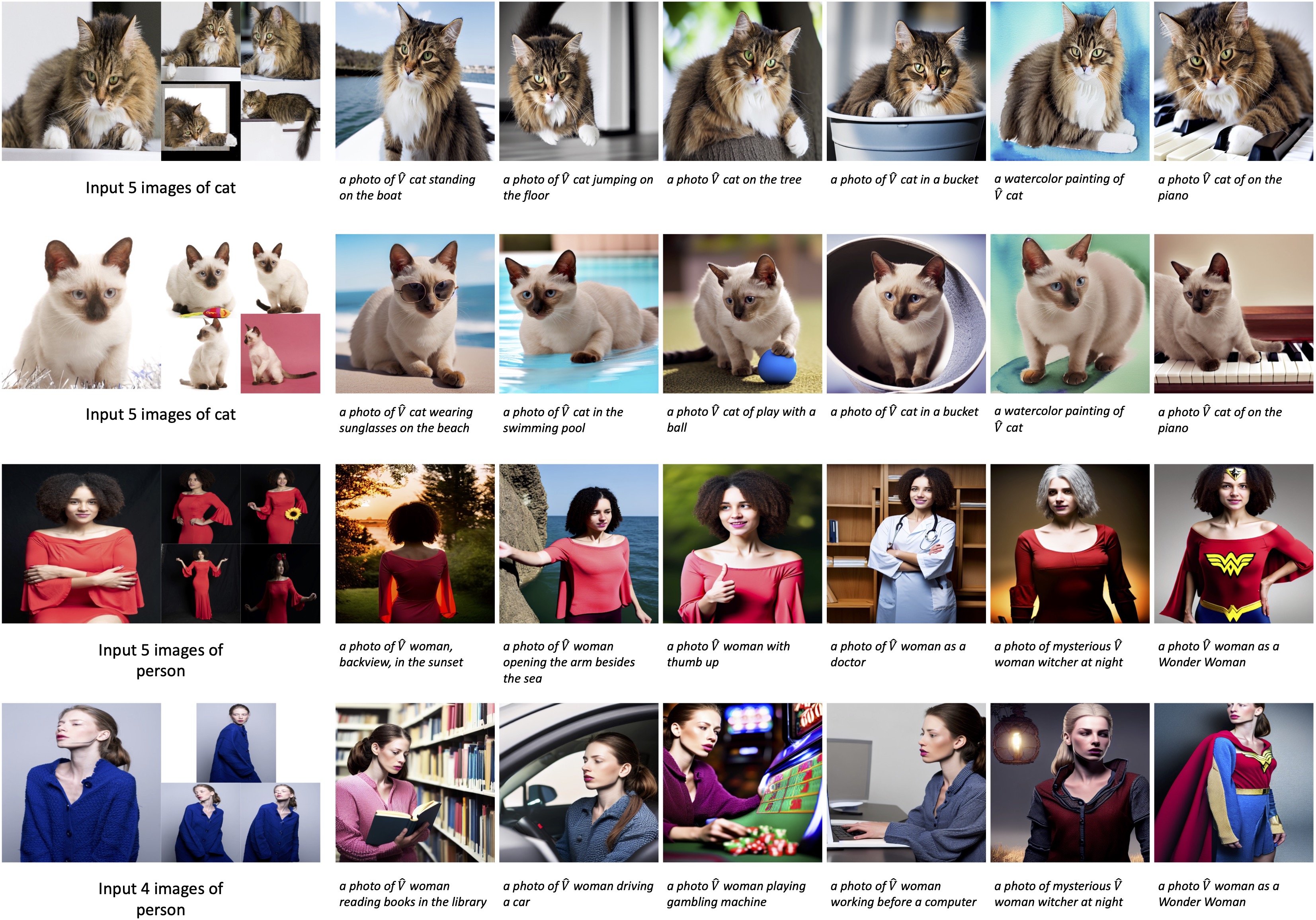
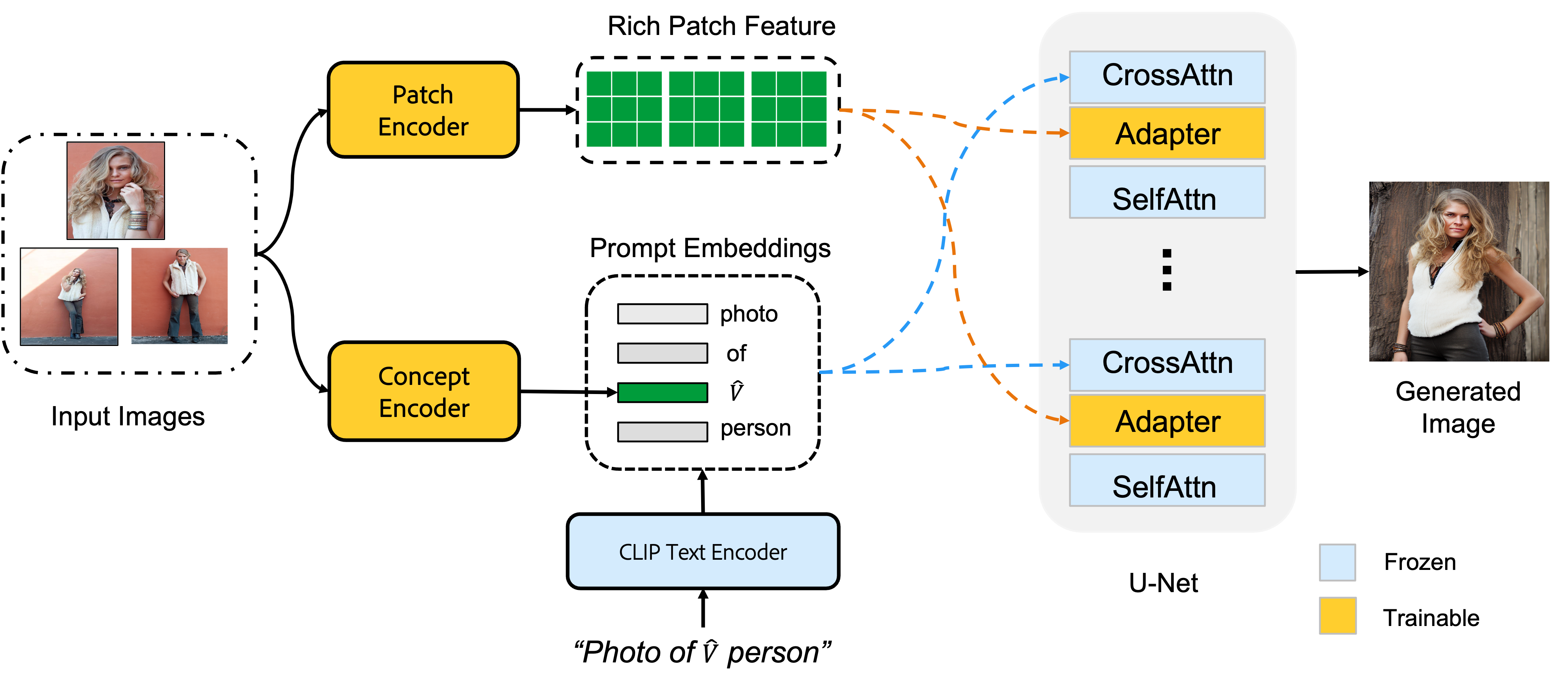
 An overview of our approach. We first inject a unique identifier $\hat{V}$ to the original input prompt to obtain "Photo of a $\hat{V}$ person", where $\hat{V}$ represents the input concept. Then we use the concept image encoder to convert the input images to a compact textual embedding and use a frozen Text encoder to map the other words to form the final prompt embeddings. We extract rich patch feature tokens from the input images with a patch encoder and then inject them to the adapter layers for better identity preservation. The U-Net of the pre-trained diffusion model takes the prompt embeddings and the rich visual feature as conditions to generate new images of the input concept. During training, only the image encoders and the adapter layers are trainable, the other parts are frozen. The model is optimized with only the reconstruction loss of the diffusion model. (We omit the object masks of the input images for simplicity.).
An overview of our approach. We first inject a unique identifier $\hat{V}$ to the original input prompt to obtain "Photo of a $\hat{V}$ person", where $\hat{V}$ represents the input concept. Then we use the concept image encoder to convert the input images to a compact textual embedding and use a frozen Text encoder to map the other words to form the final prompt embeddings. We extract rich patch feature tokens from the input images with a patch encoder and then inject them to the adapter layers for better identity preservation. The U-Net of the pre-trained diffusion model takes the prompt embeddings and the rich visual feature as conditions to generate new images of the input concept. During training, only the image encoders and the adapter layers are trainable, the other parts are frozen. The model is optimized with only the reconstruction loss of the diffusion model. (We omit the object masks of the input images for simplicity.).
|