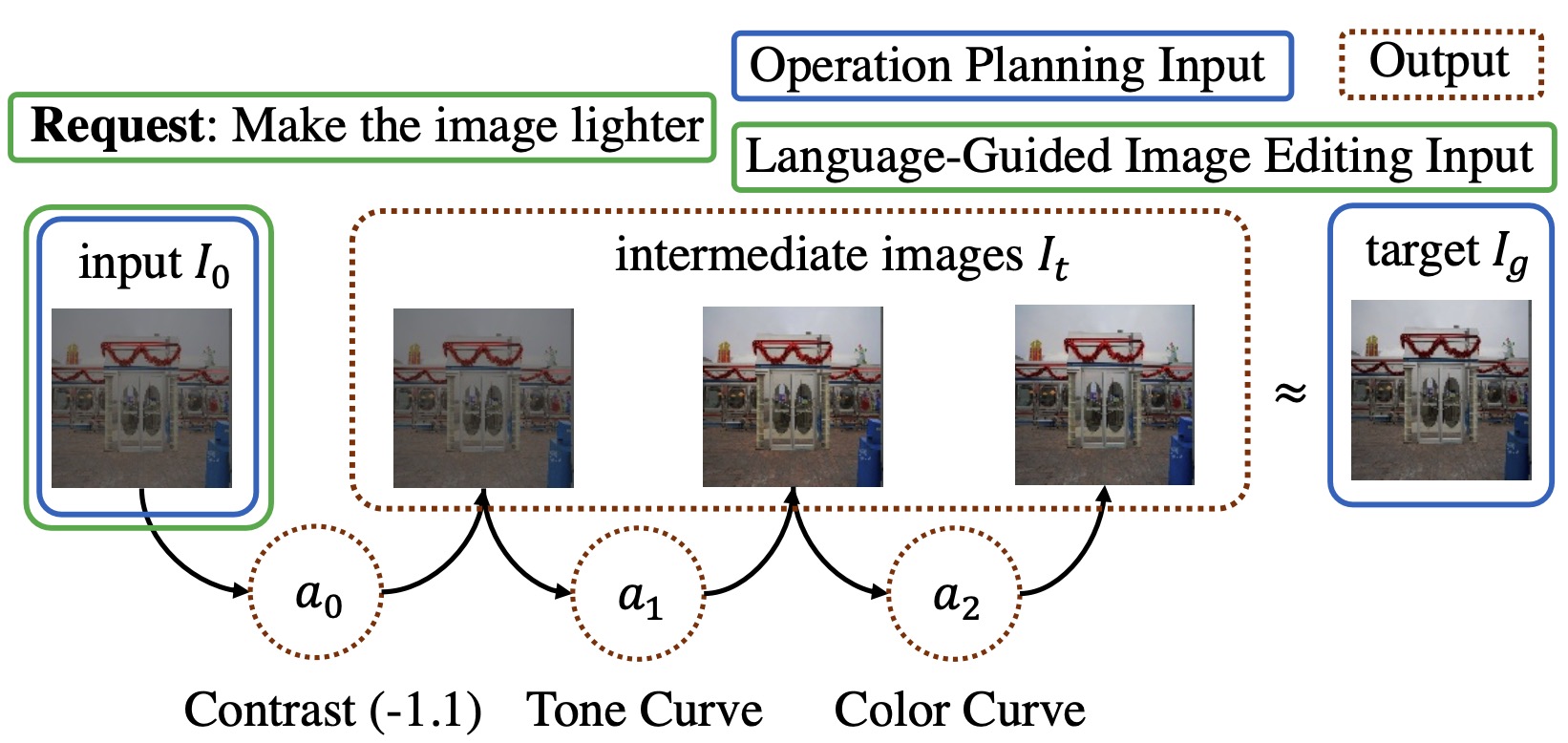
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Download Dataset |
Video |
 Visualization |
GitHub Repo |
Related Work |

|

|
 |
 |
| Compared with the GAN-based method GeNeVa and Pix2pixAug, although all the methods conduct the correct editing, our method has no pixel distortion and is independent to image resolution. This is because our editing operation is resolution-independent. |
 |
| Visualization for diversified output given the same input and request by sampling the operation parameter at inference stage. |
 |
| By adding a segmentation model to get object masks and add the operation “inpainting”, the operation planning algorithm can be extended to local editing. The recovered output is the planning result that is similar to target image |
|
Check its README to see the data structure. |
 |
Jing Shi, Ning Xu, Yihang Xu, Trung Bui, Franck Dernoncourt, Chenliang Xu Learning by Planning: Language-Guided Global Image Editing In CVPR, 2021. (ArXiv) |
Acknowledgements |
Contact |